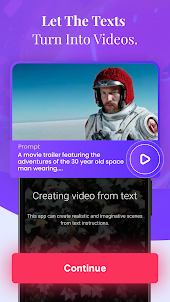
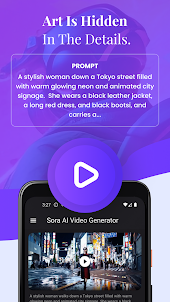
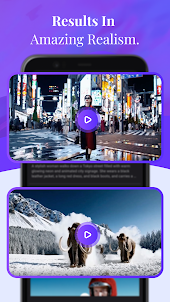
การสร้างวิดีโอจากข้อความ
Sora เป็นโมเดล AI ที่สามารถสร้างฉากที่สมจริงและจินตนาการจากคำสั่งข้อความ
เรากำลังสอน AI ให้เข้าใจและจำลองโลกทางกายภาพที่กำลังเคลื่อนไหว โดยมีเป้าหมายในการฝึกอบรมโมเดลที่ช่วยให้ผู้คนแก้ปัญหาที่ต้องมีปฏิสัมพันธ์ในโลกแห่งความเป็นจริง
ขอแนะนำ Sora โมเดลการแปลงข้อความเป็นวิดีโอของเรา Sora สามารถสร้างวิดีโอที่มีความยาวสูงสุดหนึ่งนาทีโดยยังคงรักษาคุณภาพของภาพและการยึดมั่นในการแจ้งเตือนของผู้ใช้
โซระสามารถสร้างฉากที่ซับซ้อนด้วยตัวละครหลายตัว การเคลื่อนไหวประเภทเฉพาะ และรายละเอียดที่แม่นยำของวัตถุและพื้นหลัง แบบจำลองนี้ไม่เพียงแต่เข้าใจถึงสิ่งที่ผู้ใช้ร้องขอในข้อความแจ้งเท่านั้น แต่ยังเข้าใจถึงสิ่งเหล่านั้นมีอยู่ในโลกทางกายภาพอีกด้วย
โมเดลนี้มีความเข้าใจภาษาอย่างลึกซึ้ง ทำให้สามารถตีความข้อความแจ้งได้อย่างแม่นยำ และสร้างตัวละครที่น่าสนใจซึ่งแสดงอารมณ์ความรู้สึกที่มีชีวิตชีวา Sora ยังสามารถสร้างภาพหลายภาพภายในวิดีโอที่สร้างขึ้นเพียงวิดีโอเดียวที่คงลักษณะตัวละครและสไตล์ภาพได้อย่างแม่นยำ
ความปลอดภัย
เราจะดำเนินการตามขั้นตอนด้านความปลอดภัยที่สำคัญหลายประการก่อนที่จะทำให้ Sora พร้อมใช้งานในผลิตภัณฑ์ของ OpenAI เรากำลังทำงานร่วมกับทีมงานสีแดง — ผู้เชี่ยวชาญด้านโดเมนในด้านต่างๆ เช่น ข้อมูลที่ไม่ถูกต้อง เนื้อหาแสดงความเกลียดชัง และอคติ — ซึ่งจะเป็นผู้ทดสอบโมเดลแบบตรงข้าม
เทคนิคการวิจัย
Sora เป็นโมเดลการแพร่กระจาย ซึ่งสร้างวิดีโอโดยเริ่มจากวิดีโอที่ดูเหมือนสัญญาณรบกวนคงที่ และค่อยๆ แปลงมันโดยกำจัดสัญญาณรบกวนออกไปหลายขั้นตอน
Sora สามารถสร้างวิดีโอทั้งหมดพร้อมกันหรือขยายวิดีโอที่สร้างขึ้นเพื่อให้ยาวขึ้นได้ ด้วยการให้โมเดลมองเห็นล่วงหน้าของหลายๆ เฟรมในแต่ละครั้ง เราได้แก้ไขปัญหาที่ท้าทายในการทำให้แน่ใจว่าวัตถุจะยังคงเดิมแม้ว่าจะอยู่นอกการมองเห็นชั่วคราวก็ตาม
Sora เป็นโมเดล AI ที่สามารถสร้างฉากที่สมจริงและจินตนาการจากคำสั่งข้อความ
เรากำลังสอน AI ให้เข้าใจและจำลองโลกทางกายภาพที่กำลังเคลื่อนไหว โดยมีเป้าหมายในการฝึกอบรมโมเดลที่ช่วยให้ผู้คนแก้ปัญหาที่ต้องมีปฏิสัมพันธ์ในโลกแห่งความเป็นจริง
ขอแนะนำ Sora โมเดลการแปลงข้อความเป็นวิดีโอของเรา Sora สามารถสร้างวิดีโอที่มีความยาวสูงสุดหนึ่งนาทีโดยยังคงรักษาคุณภาพของภาพและการยึดมั่นในการแจ้งเตือนของผู้ใช้
โซระสามารถสร้างฉากที่ซับซ้อนด้วยตัวละครหลายตัว การเคลื่อนไหวประเภทเฉพาะ และรายละเอียดที่แม่นยำของวัตถุและพื้นหลัง แบบจำลองนี้ไม่เพียงแต่เข้าใจถึงสิ่งที่ผู้ใช้ร้องขอในข้อความแจ้งเท่านั้น แต่ยังเข้าใจถึงสิ่งเหล่านั้นมีอยู่ในโลกทางกายภาพอีกด้วย
โมเดลนี้มีความเข้าใจภาษาอย่างลึกซึ้ง ทำให้สามารถตีความข้อความแจ้งได้อย่างแม่นยำ และสร้างตัวละครที่น่าสนใจซึ่งแสดงอารมณ์ความรู้สึกที่มีชีวิตชีวา Sora ยังสามารถสร้างภาพหลายภาพภายในวิดีโอที่สร้างขึ้นเพียงวิดีโอเดียวที่คงลักษณะตัวละครและสไตล์ภาพได้อย่างแม่นยำ
ความปลอดภัย
เราจะดำเนินการตามขั้นตอนด้านความปลอดภัยที่สำคัญหลายประการก่อนที่จะทำให้ Sora พร้อมใช้งานในผลิตภัณฑ์ของ OpenAI เรากำลังทำงานร่วมกับทีมงานสีแดง — ผู้เชี่ยวชาญด้านโดเมนในด้านต่างๆ เช่น ข้อมูลที่ไม่ถูกต้อง เนื้อหาแสดงความเกลียดชัง และอคติ — ซึ่งจะเป็นผู้ทดสอบโมเดลแบบตรงข้าม
เทคนิคการวิจัย
Sora เป็นโมเดลการแพร่กระจาย ซึ่งสร้างวิดีโอโดยเริ่มจากวิดีโอที่ดูเหมือนสัญญาณรบกวนคงที่ และค่อยๆ แปลงมันโดยกำจัดสัญญาณรบกวนออกไปหลายขั้นตอน
Sora สามารถสร้างวิดีโอทั้งหมดพร้อมกันหรือขยายวิดีโอที่สร้างขึ้นเพื่อให้ยาวขึ้นได้ ด้วยการให้โมเดลมองเห็นล่วงหน้าของหลายๆ เฟรมในแต่ละครั้ง เราได้แก้ไขปัญหาที่ท้าทายในการทำให้แน่ใจว่าวัตถุจะยังคงเดิมแม้ว่าจะอยู่นอกการมองเห็นชั่วคราวก็ตาม
เพิ่มเติม